
Introduction
In the ever-evolving landscape of machine learning (ML) applications, the choice between online, offline, and stream processing methods can significantly impact the efficiency and responsiveness of machine learning models. In this article, we delve into the distinct characteristics of each approach, exploring their advantages, drawbacks, and use cases.
Online Processing (Synchronous)
Online processing is a real-time, synchronous approach to machine learning that usually involves wrapping models into a web API for serving. This method prioritizes immediate responses, making it ideal for applications requiring quick processing of user inputs.
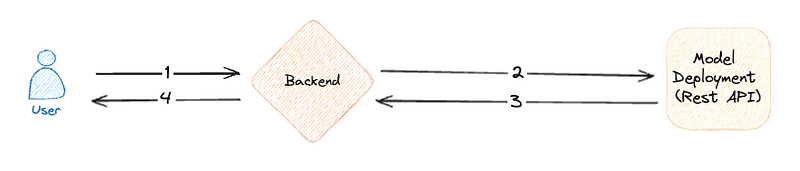
Typical Process
- User sends data for processing
- Backend sends data to the model and waits for response
- Model processes the data and returns back the prediction
- Backend sends the prediction back to the user
Pros
- This approach proves to be particularly useful for swift prototyping, thanks to its straightforward nature.
- It is recommended when the backend communications are already established using REST, offering seamless integration.
- It’s an ideal method for when the application demands a near real-time and synchronous response to ensure timely and efficient processing.
Cons
- Hosting costs can become a significant drawback, particularly when the models require a GPU.
- While scalability is good, this method may not be the most optimal solution.
- The always-online nature of the ML deployment can lead to increased energy consumption, posing additional environmental concerns.
Common use-cases
Generally, applications that require a near real-time response are a great fit for this type of processing. Such applications might include chatbots in the form of virtual assistants or customer service agents. In the field of computer vision, online processing is usually employed in face recognition or quality inspection for physical products.
Offline Processing (Batch)
Batch processing is an offline data processing method where large volumes of data are collected, processed, and analyzed in scheduled intervals rather than in real-time. Unlike online processing, which thrives on immediate interactions, batch processing involves accumulating data over a period, allowing for more cost-effective computation.
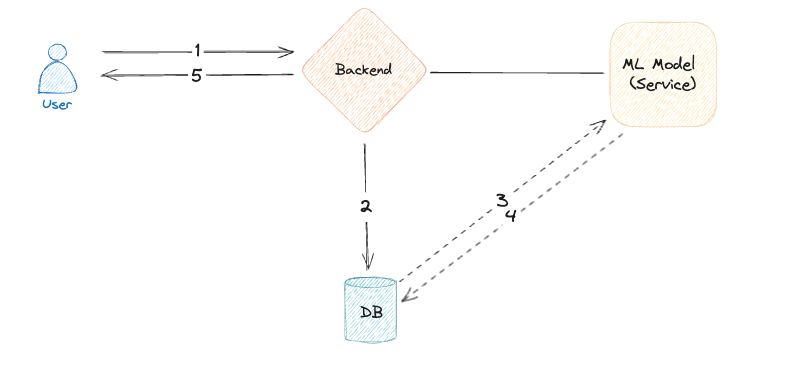
Typical Process
- User sends data for processing
- Backend saves data to the database
- Whenever the model is switched on, it processes data
- Saves predictions to database
- User asks for finished predictions and receives them
Pros
- A very cost-effective way to deploy models.
- The batch ML inference code is similar to the training code, making the deployment less prone to implementation bugs.
Cons
- It works only in scenarios where delayed results are acceptable, limiting its applicability to specific use cases.
- Might need bulky computing resources and/or big data tools to process huge volumes of data as they accumulate over time.
Common use-cases
Common batch processing applications are recommendation engines where they periodically generate suggestions for a large number of users. Another suitable use case is weather forecasting that’s computed on a weekly or monthly basis. Long-term economic forecasting, credit risk analysis, or other kinds of big data reporting are also deployed as batch processing since an instant response isn’t required.
Stream Processing (Asynchronous)
Stream processing, in the context of machine learning, is an asynchronous method that excels in handling continuous and dynamic data streams. In this approach, data is processed in real-time as it flows through the system, enabling quick and efficient analysis. Utilizing message queues as a fundamental component, stream processing systems can handle high volumes of data asynchronously by decoupling the production and consumption of information.
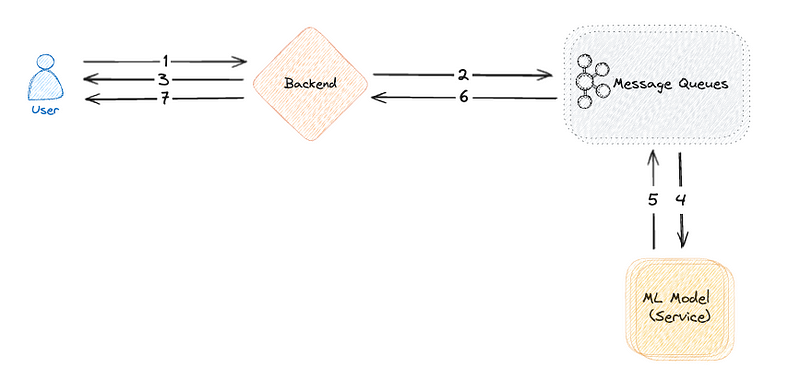
Typical Process
- User sends data for processing
- Backend sends data to the message queue
- Backend sends confirmation back to the user
- Whenever model is available, it processes data
- Model sends predictions to the message queue
- Backend sends predictions to the user
Pros
- The ML deployments can be activated on demand, making it more cost-effective than online synchronous processing
- Scales very well and is robust to traffic spikes
Cons
- Requires more software engineering expertise to build
- Due to its complexity, it’s harder to maintain and debug
Common use-cases
Stream processing stands out for its proficiency in real-time processing and impressive scalability. Several use cases can be found in the IoT sector, demonstrated by applications like traffic management, predictive routing and efficient energy management. It can also be used for dynamic pricing in the e-commerce industry and also plays an important role in fraud detection systems. The instantaneous processing of streaming data proves crucial for identifying and responding to potential threats in real-time.
Conclusion
The choice between online, offline, and stream processing methods in machine learning has implications for the efficiency and responsiveness of the solution. It’s important to note that an ML system might involve deploying multiple models using a combination of these methods. Ultimately, the decision depends on the nature of the task at hand, emphasizing the importance of thoughtful consideration of requirements and objectives.
Thanks a lot for reading! Until next time, take care and stay curious!
Resources
- https://www.oreilly.com/library/view/designing-machine-learning/9781098107956/
- https://dev.to/code_jedi/machine-learning-model-deployment-with-fastapi-and-docker-llo
- https://www.knowledgehut.com/blog/big-data/5-best-data-processing-frameworks
- https://mlserver.readthedocs.io/en/latest/examples/kafka/README.html
- https://neptune.ai/blog/ml-model-serving-best-tools