
Introduction
Undoubtedly, the recent advances in Natural Language Processing(NLP) with the use of the transformer — neural networks are truly remarkable. These models can perform different kinds of tasks such as translation, text summarization and auto-completion very decently. A different variation of a transformer, the vision transformer is the current state of the art for many computer vision tasks among image classification and object detection.

In order to train these models we need large amounts of data, expertise and computational power. Unfortunately, these can be quite expensive for medium-small sized businesses and individuals.
The aim of this article is to take a step back from the AI hype and provide an alternative approach to this NLP task. In the next sections we will see how to “talk” to a database using natural language — plain English without the need to train any machine learning algorithms.
The Procedure
The first step is to preprocess the user input with the combination of several rule-based natural language processing techniques such as tokenization, lemmatization and POS tagging.
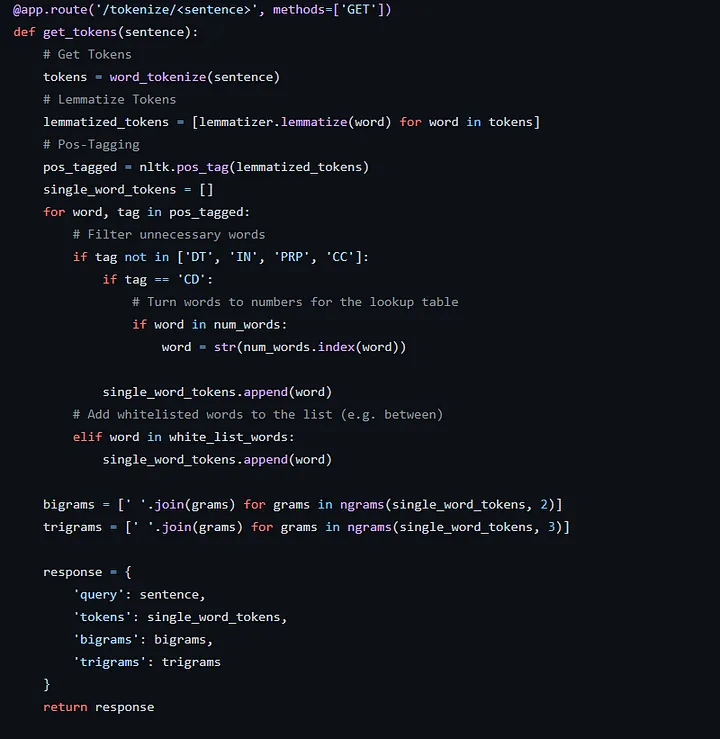
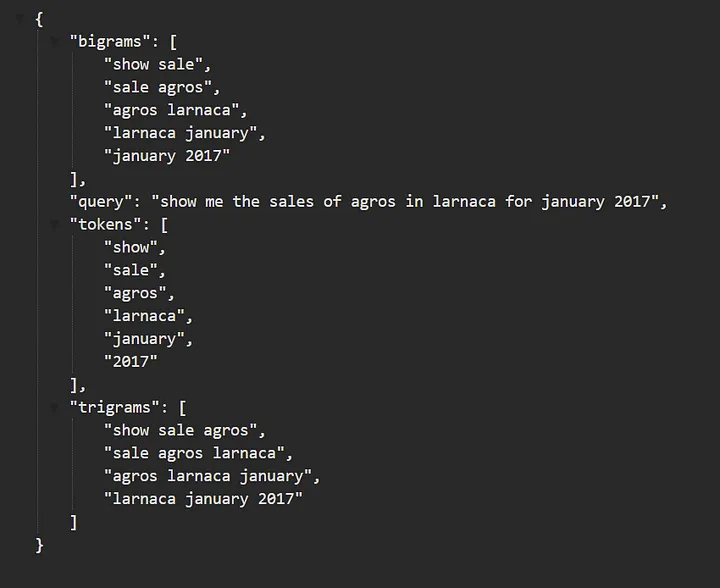
For example, providing the input “show me the sales of agros in larnaca for january 2017” returns the response as shown below. You can also play with the API, let me know if you find any bugs or have any suggestions.
Next, we create a flat table as a representation of our database schema. The reason is because it’s more straightforward to query a single table rather than joining multiple ones.
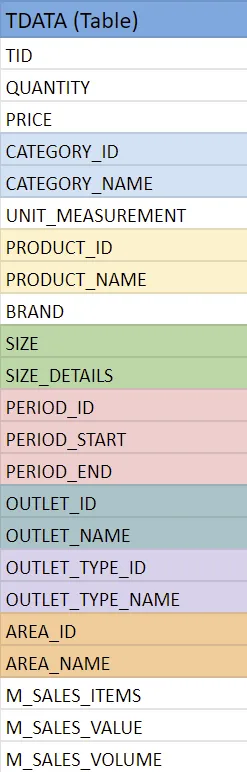
In the example above, just by the column names, we can recognize at least 7 different tables merged into 1.
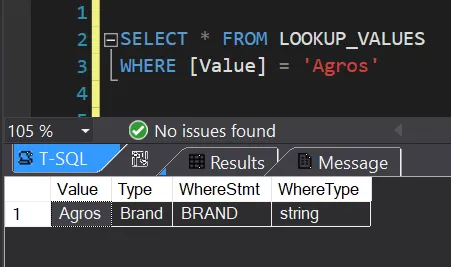
The other part which takes place at the database level is the mapping view. This view helps us find out the meaning of each token/word but also get its equivalent column name in SQL. For example, given the word “Agros”, we want to conclude that it is actually a brand.
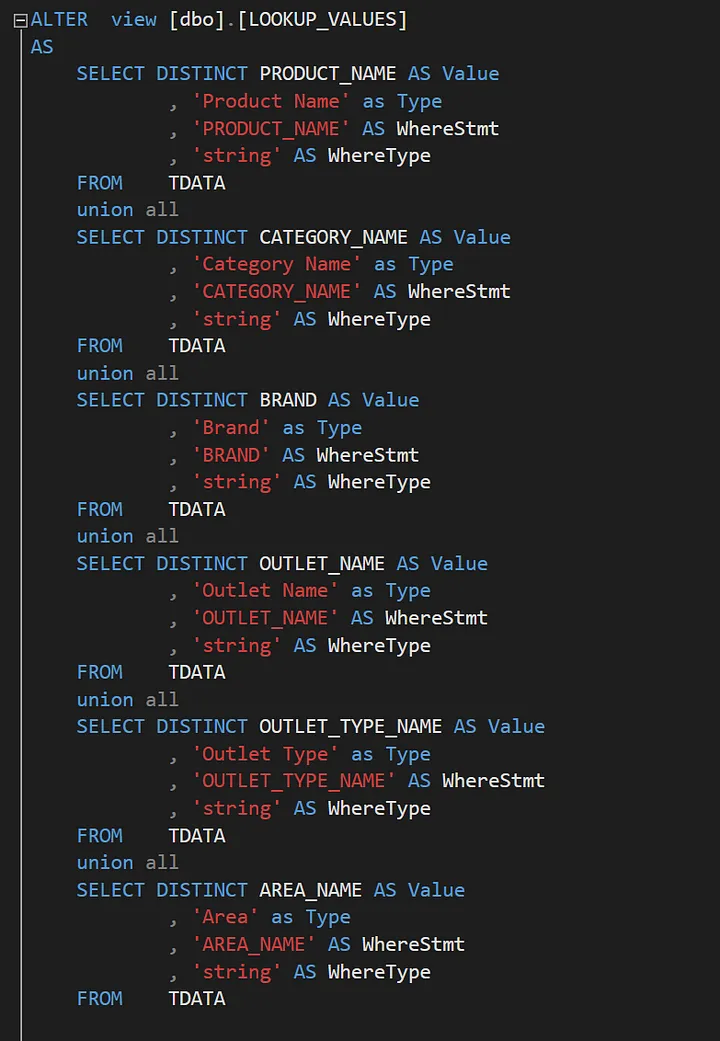
A part of the view is shown in the image above. Even though it might look confusing and unintuitive at first, it makes sense once we understand the role it plays at generating the SQL. For as many tokens as we have, we query the view and filter by the value of our token (or bigram).
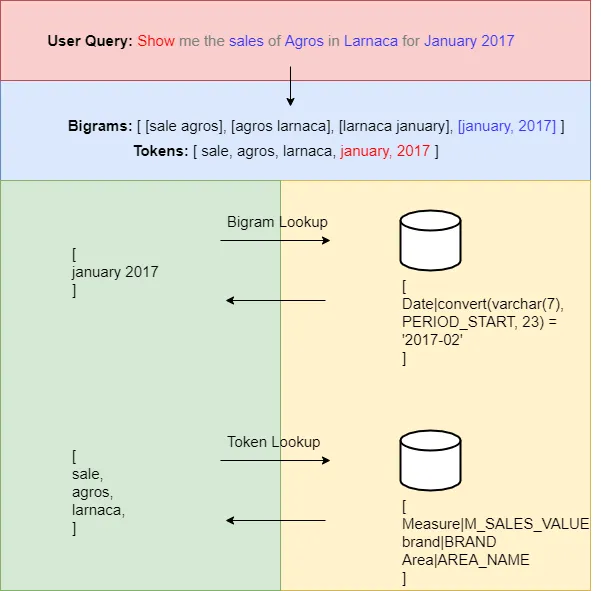
The image below shows the tokenization and mapping procedure at a high level. We start by providing the user query and then generate the bigrams and tokens. We do a bigram lookup and delete these words from our tokens for efficiency purposes.
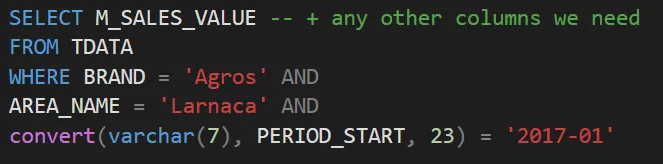
Once we are done with the mapping, we can construct the SQL by combining everything together programmatically. We concatenate each lookup with an “AND” statement and finally we execute the query to get the results.
Conclusion
Even though this system is not as intelligent and cannot generalize as machine learning based systems do, it provides a cheaper and faster solution which is tailored for this specific task.
Until next time, thank you for reading!
This article explains a part of my undergraduate thesis project, you can find a demo along with the source code in this GitHub repo.